Obecnie programiści dużo rzadziej zwracają uwagę na to, ile pamięci zużywa aplikacja, nad którą pracują. Komputery osobiste mają gigantyczne zasoby RAMu, spokojnie wystarczające do obsługi zasobochłonnych aplikacji, głównie gier. Pamięć wirtualna pozwala z kolei uwolnić się od zmartwień o pamięć fizyczną, ot najwyżej dysk będzie trochę chrobotał od czasu do czasu. Programiści z kolei mają dodatkowo do dyspozycji języki programowania, w których praktycznie wcale nie muszą się martwić o zarządzanie pamięcią. Problem poprawnej alokacji i dealokacji załatwiają przeróżne garbage collectory.
Są jednak takie obszary, w których programiści muszą się liczyć z ograniczonymi zasobami. Jednym z takich obszarów jest oprogramowanie serwerowe, szczególnie takie, które w założeniu musi być wysokowydajne, na przykład takie, które relizuje strumieniowanie multimediów. Aplikacja musi utrzymywać po swojej stronie znaczne bufory na ramki wideo dla poszczególnych plików/kanałów. Zbyt wielu użytkowników naraz i nagle pamięć fizyczna ulega wyczerpaniu, co doprowadza do swap’owania aktualnie nieużywanych stron pamięci na dysk. To z kolei powoduje olbrzymi spadek wydajności aplikacji i może doprowadzić do problemów z funkcjonowaniem usług.
Drugim obszarem są systemy wbudowane (embedded). Z reguły zasoby takich komputerów są mocno ograniczone i o rzędy wielkości mniejsze, niż zasoby komputerów osobistych. Mimo, że w wielu architekturach jednostka zarządzania pamięcią (MMU – Memory Management Unit) jest dostępna i wykorzystywana przez system, to może się okazać, że nie ma co liczyć na swap. Ale nierzadko MMU zwyczajnie nie ma, a pamięć fizyczna jest adresowana wprost. Wtedy zarządzanie pamięcią staje się jednym z kluczowych zadań – programista nagle zaczyna zwracać uwagę na takie subtelności, jak wielkość pliku wykonywalnego, wielkości bibliotek, rozmiary stosów, alokacje statyczne podczas inicjalizacji.
Niezależnie od charakteru tworzonej aplikacji, zawsze warto wiedzieć, jak sprawdzić zużycie pamięci przez proces, stąd kilka rad.
1. ps u
Dlaczego nie skorzystać z ps-a? Wyświetla sporo informacji o procesach, a z argumentem ‘u’ dodatkowo podaje pewne informacje na temat zużycia pamięci.
|
1 2 3 4 5 6 7 8 9 10 11 |
x:~$ ps u USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND gs 15867 0.0 0.0 27908 3852 pts/0 Ss kwi23 0:00 bash gs 16506 0.0 0.0 27848 3772 pts/2 Ss kwi23 0:00 bash gs 23768 0.1 0.0 193460 3876 pts/0 Sl+ 00:21 0:00 ./myApp config.xml gs 23787 0.0 0.0 23864 1324 pts/2 R+ 00:24 0:00 ps u |
VSZ jest tutaj całkowitym zaalokowanym rozmiarem pamięci wirtualnej. Wielkości podawane są w kilobajtach. Widać, że myApp ma dość kosmiczne wymagania, a to głównie dlatego, że linkuje się z kilkunastoma wielkimi bibliotekami do przetwarzania multimediów. RSS określa tutaj zestaw roboczy stron, czyli wielkość fizycznej pamięci, zajmowanej aktualnie przez proces. VSZ można by rozumieć jako deklarację procesu odnośnie tego, ile miejsca mógłby zająć, gdyby chciał się zmieścić w RAMie w całości. RSS mówi ile pamięci fizycznej jest aktualnie w użyciu.
Po obciążeniu aplikacji myApp masą roboty uzyskamy całkiem inny obraz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
x:~$ ps u USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND gs 15867 0.0 0.0 27908 3852 pts/0 Ss kwi23 0:00 bash gs 16506 0.0 0.0 27848 3772 pts/2 Ss kwi23 0:00 bash gs 23768 4.4 1.2 796512 97512 pts/0 Sl+ 00:21 0:17 ./myApp config.xml gs 23912 0.0 0.0 27904 3840 pts/3 Ss 00:27 0:00 bash gs 24058 0.0 0.0 23864 1328 pts/2 R+ 00:28 0:00 ps u |
VSZ podskoczył do prawie 800 MB, a RSS aż do 100 MB. Teraz zastanawiam się, czy mój program cały czas zużywał 100MB RAMu, czy może bywał bardziej zachłanny w trakcie swojego działania.
2. top
Co powie mi top? W zasadzie to samo, VIRT to inaczej VSZ, RES to RSS, a SHR to pamięć współdzielona z innymi procesami. Niewątpliwie zaletą jest tutaj stały podgląd zużycia zasobów, procesora i pamięci na tle innych procesów. Jeśli w aplikacji znalazłby się znaczny wyciek pamięci, to dałoby się to zaobserwować statytykach top-a.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
top - 00:44:18 up 1 day, 12:01, 5 users, load average: 0,52, 0,39, 0,40 Tasks: 266 total, 3 running, 263 sleeping, 0 stopped, 0 zombie %Cpu(s): 7,9 us, 0,9 sy, 3,9 ni, 86,4 id, 0,8 wa, 0,0 hi, 0,0 si, 0,0 st KiB Mem: 8058880 total, 7890664 used, 168216 free, 28060 buffers KiB Swap: 8270844 total, 21360 used, 8249484 free, 5094536 cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24217 gs 20 0 777m 95m 4560 S 46,3 1,2 0:12.68 myApp 13357 gs 20 0 2251m 1,2g 47m S 12,6 15,8 107:58.76 firefox 2253 gs 20 0 1539m 104m 33m S 9,3 1,3 25:26.43 compiz 21505 gs 20 0 755m 99m 29m R 9,3 1,3 27:04.70 plugin-containe 16588 gs 20 0 1505m 88m 35m S 9,0 1,1 0:15.45 vlc 1086 root 20 0 836m 310m 271m S 8,7 3,9 40:17.83 Xorg 15857 gs 20 0 645m 22m 12m S 4,7 0,3 0:09.70 gnome-terminal 1930 gs 20 0 430m 18m 2856 S 1,0 0,2 0:56.48 ibus-daemon 1999 gs 20 0 638m 67m 11m S 0,7 0,9 8:05.16 unity-panel-ser 8137 gs 20 0 1237m 73m 26m S 0,7 0,9 8:31.72 codeblocks 23347 gs 20 0 756m 94m 55m S 0,7 1,2 0:28.35 spotify 23405 gs 20 0 887m 25m 13m S 0,7 0,3 0:12.06 SpotifyHelper 17 root 20 0 0 0 0 R 0,3 0,0 0:17.89 rcu_sched 20 root 20 0 0 0 0 S 0,3 0,0 0:04.27 rcuos/2 971 root 20 0 4376 708 532 S 0,3 0,0 0:57.07 acpid 1957 gs 20 0 373m 33m 4968 S 0,3 0,4 1:00.42 hud-service |
3. /proc/<pid>/status
Naprawde przydatne informacje odnośnie pamięci kryją się w /proc/<pid>/status:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
gs@gs-X750JB:~$ cat /proc/24217/status Name: myApp State: S (sleeping) Tgid: 24217 Pid: 24217 PPid: 15867 TracerPid: 0 Uid: 1000 1000 1000 1000 Gid: 1000 1000 1000 1000 FDSize: 256 Groups: 4 24 27 30 46 112 124 1000 VmPeak: 862048 kB VmSize: 792992 kB VmLck: 0 kB VmPin: 0 kB VmHWM: 102468 kB VmRSS: 100196 kB VmData: 696340 kB VmStk: 136 kB VmExe: 184 kB VmLib: 19896 kB VmPTE: 508 kB VmSwap: 0 kB Threads: 9 SigQ: 0/62560 SigPnd: 0000000000000000 ShdPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: 0000000000000000 SigCgt: 0000000180000000 CapInh: 0000000000000000 CapPrm: 0000000000000000 CapEff: 0000000000000000 CapBnd: 0000001fffffffff Seccomp: 0 Cpus_allowed: ff Cpus_allowed_list: 0-7 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0 voluntary_ctxt_switches: 12 nonvoluntary_ctxt_switches: 54 |
VmSize jest znaną skądinąd wielkością pamięci wirtualnej zaalokowanej przez proces ale już VmPeak podaje szczytową wartość zaalkoowanej pamięci wirtualnej, co jest dużo przydatniejszą informacją. Podobnie sprawa wygląda z wielkością pamięci fizycznej wykorzystywanej przez proces, czyli VmRSS. VmHWM jest szczytowym zużyciem pamięci fizycznej przez proces (HWM to skrót od high water mark co dosłownie oznacza najwyższy odczyt na wodowskazie, analogia dość celna). Mamy też dość bezużyteczne pola jak VmData i VmStk. VmStk podaje wielkość stosu wątku głównego, dość bezużyteczna informacja w przypadku aplikacji wielowątkowych. Z kolei VmData zmienia się proporcjonalnie do VmSize, ponieważ VmData jest sumą rozmiarów segmentów kodu (text), segmentów danych statycznych (bss) i segmentu danych (data) – zawierającego stertę oraz rozmiaru stosu. Wartość jest zawsze niższa niż VmSize ale bardziej wiarygodna, ponieważ VmSize podaje również wielkość stron mapowanych w pamięci wirtualnej ale jednocześnie nieużywalnych (PROT_NONE). Tak więc VmSize w zasadzie daje nam informację o całkowitym stopniu zużycia przestrzeni adresowej, podczas gdy VmData podaje ile z tej przestrzeni adresowej w ogóle może być użyte przez proces, ponieważ zawiera kod lub dane. Tutaj jest to dośc wyczerpująco opisane.
Jest jeszcze VmSwap, które podaje wielkośc pamięci wyswapowanej na dysk. Niestety nie ma tutaj informacji o szczytowej wielkości swap’u. Jednak gdyby zdarzyło nam się zaobserwować VmSwap > 0, to znaczy, że nie mieścimy się w fizycznej pamięci, co może być alarmujące.
4. /proc/<pid>/smaps
Tutaj znajdziemy mapę pamięci naszego procesu – wylistowane wszystkie obszary pamięci wirtualnej, jakie alokuje nasz proces. Do tych obszarów zaliczają się też te zaalokowane w bibliotekach współdzielonych. W moim przypadku każda z bibliotek, a jest ich kilkanaście, alokuje dodatkowe 2MB pamięci wirtualnej której nie używa i nigdy nie użyje (patrz VmSize wyżej) – jest to pewien mechanizm linkera, wyjaśniony tutaj, który ma zapewnić poprawne współdzielenie bibliotek między procesami. To niestety powoduje, że nawet małe zgrabne aplikacyjki, ale wykorzystujące bardzo wiele bibliotek dynamicznych, podczas działania pożerają gigantyczną częśc przestrzeni adresowej, mimo, że faktycznie nie zużywają nawet promila tego, co pokazuje VmSize.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
7f41b13ce000-7f41b14c5000 r-xp 00000000 08:02 54003358 /usr/lib/x86_64-linux- gnu/libavformat.so.53.21.1 Size: 988 kB Rss: 560 kB Pss: 560 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 560 kB Private_Dirty: 0 kB Referenced: 560 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd ex mr mw me ?? 7f41b14c5000-7f41b16c4000 ---p 000f7000 08:02 54003358 /usr/lib/x86_64-linux- gnu/libavformat.so.53.21.1 Size: 2044 kB Rss: 0 kB Pss: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 0 kB Referenced: 0 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: mr mw me ?? 7f41b16c4000-7f41b16ca000 r--p 000f6000 08:02 54003358 /usr/lib/x86_64-linux-gnu/libavformat.so.53.21.1 Size: 24 kB Rss: 24 kB Pss: 24 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 24 kB Referenced: 24 kB Anonymous: 24 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr mw me ac ?? 7f41b16ca000-7f41b16d7000 rw-p 000fc000 08:02 54003358 /usr/lib/x86_64-linux-gnu/libavformat.so.53.21.1 Size: 52 kB Rss: 52 kB Pss: 52 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 52 kB Referenced: 52 kB Anonymous: 52 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac ?? 021b4000-021d5000 rw-p 00000000 00:00 0 [heap] Size: 132 kB Rss: 132 kB Pss: 132 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 132 kB Referenced: 132 kB Anonymous: 132 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac ?? |
“VmFlags: rd ex” oznacza obszar pamięci z kodem wykonywalnym, “VmFlags: rd” to dane tylko do odczytu, natomiast “VmFlags: rd wr” to pamięć swobodnie dostępna, czyli np. stos lub sterta. Przy czym sterta niekoniecznie musi mieć w wydruku z /proc/xxx/smaps etykietę [heap]. Większe alokacje, powyżej MMAP_THRESHOLD na pewno nie będą jej miały, a dodatkowo biblioteki współdzielone mogą implementować własne zarządzanie pamięcią, pomijając malloc/new i korzystając z własnych mechanizmów a następnie z mmap().
Widać tutaj też tę, zagadkową do niedawna, 2MB “dziurę” (2044 kB) w przestrzeni adresowej między obszarem kodu a obszarem danych.
Dzięki smaps możemy przekonać się, jaka jest struktura pamięci wirtualnej wykorzystywanej przez proces i skąd bierze się wartość VmSize i VmRSS. Możemy się dowiedzieć również, które obszary są aktualnie wyswapowane na dysk. Jednak przydałaby się możliwość stałego monitorowania zużycia pamięci w czasie. Są do tego niezliczone skrypty, w większości korzystające z danych w /proc/ . Zamiast jednak obserwować proces z zewnątrz, można skorzystać z profilera pamięci, czyli w pewnym sensie obserwować zjawiska zachodzące wewnątrz procesu.
5. Valgrind Massif
Valgrind jest aktualnie najbardziej wszechstronnym profilerem do debugowania problemów z pamięcią. Głównie załatwia się przy jego pomocy wycieki pamięci i mazanie po stercie (heap corruption) – na problemy ze stertą, szczególnie w oprogramowaniu wielowątkowym, naprawdę nie ma zbyt wielu sposobów, oprócz Valgrinda jest jeszcze dmalloc lub Electric Fence. Jednak nie nadają się one do monitorowania zużycia pamięci. Do tych zadań Valgrind ma narzędzie o nazwie massif. Domyślnie rejestruje ono wszelkie alokacje i dealokacje wywołane za pomocą malloc()/free() i new/delete, jednak można skłonić to narzędzie do rejestrowania na niższym poziome, czyli alokacje poprzez mmap/mremap/brk (–pages-as-heap=yes), które operują na całych stronach (4kB).
Po wywołaniu Valgrinda z Massifem dostajemy plik z próbkami, w zasadzie nieczytelny, stąd jak w przypadku innych profilerów mamy narzędzia do wizualizacji danych. Valgrind znacznie spowalnia naszą aplikację, w wielu przypadkach z aplikacji w ogóle nie da się korzystać podczas profilowania, co nie znaczy, że nie da się wyśledzić problemów i ich przyczyn.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
x:~/y$ valgrind --tool=massif ./myApp config.xml ==27213== Massif, a heap profiler ==27213== Copyright (C) 2003-2012, and GNU GPL'd, by Nicholas Nethercote ==27213== Using Valgrind-3.8.1 and LibVEX; rerun with -h for copyright info ==27213== Command: ./myApp config.xml ==27213== ^C==27213== Killed x:~/y$ ls -l mas* -rw------- 1 gs gs 121053 kwi 23 11:19 massif.out.16475 -rw------- 1 gs gs 105778 kwi 23 11:20 massif.out.16490 -rw------- 1 gs gs 98409 kwi 24 11:42 massif.out.27213 x:~/y$ ms_print massif.out.27213 | less -------------------------------------------------------------------------------- Command: ./myApp config.xml Massif arguments: (none) ms_print arguments: massif.out.27213 -------------------------------------------------------------------------------- MB 109.7^ : | #:@::@@:::::::::::::::::@::::::::::::::::::::::::::::@::::::@:::::: | #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @@#:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @@@ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: | @ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: |@@ @ #:@::@ :: : ::::: ::::: @ : ::::: :::::: :::: : :::: @::::::@:::::: 0 +----------------------------------------------------------------------->Gi 0 19.94 Number of snapshots: 68 Detailed snapshots: [1, 2, 3, 4 (peak), 6, 9, 24, 49, 59] -------------------------------------------------------------------------------- n time(i) total(B) useful-heap(B) extra-heap(B) stacks(B) -------------------------------------------------------------------------------- 0 0 0 0 0 0 1 289,926,038 48,520,976 48,478,883 42,093 0 99.91% (48,478,883B) (heap allocation functions) malloc/new/new[], --alloc-fns, etc. ->79.26% (38,459,704B) 0x633CEB3: x264_malloc (in /usr/lib/x86_64-linux-gnu/libx264.so.123) | ->16.55% (8,030,208B) 0x6332A78: x264_frame_pop_unused (in /usr/lib/x86_64-linux-gnu/libx264.so.123) | | ->16.55% (8,030,208B) 0x63A9DB7: x264_encoder_open_123 (in /usr/lib/x86_64-linux-gnu/libx264.so.123) (...) |
Z narzędzia ms_print dostajemy nawet toporny ale czytelny wykresik, pokazujący zużycie pamięci w czasie, a niżej Valgrind próbuje wytknąć winowajców co większych alokacji. W pierwszej próbce za 79% zaalokowanej pamięci odpowiada enkoder x264, zresztą w kolejnych próbkach było podobnie. x264 po prostu jest żarłoczny.
A oto ładna wizualizacja wyników z massif’a, za pomocą massif-visualizer:
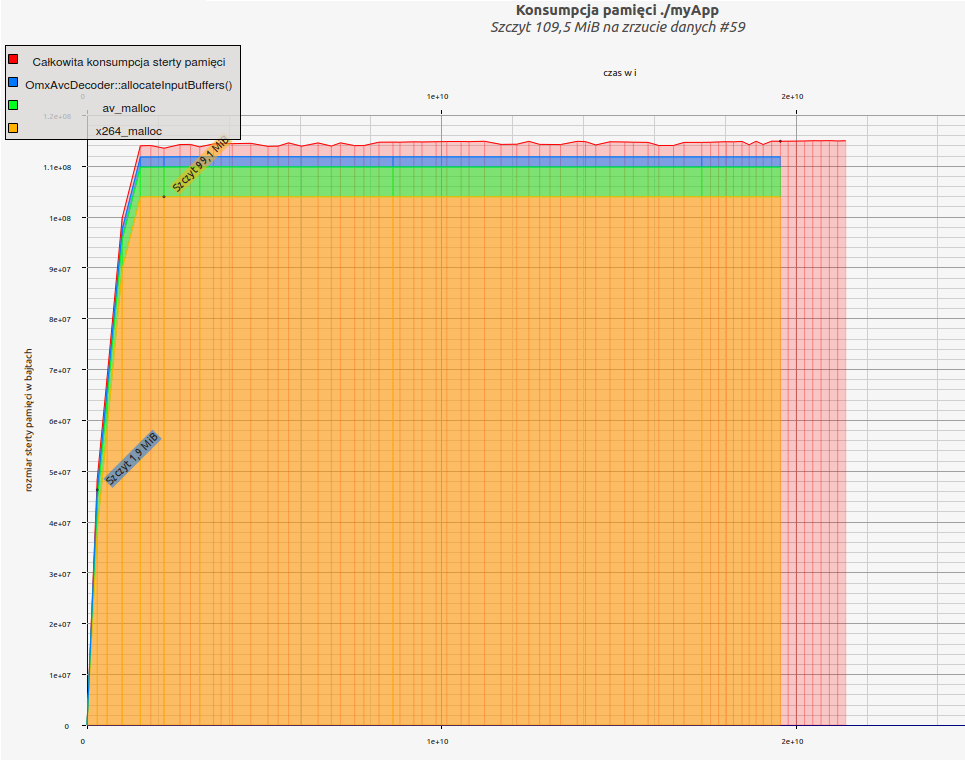
Valgrind odpowie nam na wiele pytań, na które nie byłyby nam w stanie odpowiedzieć narzędzia z pkt. 1-4 – na przykłąd skąd się biorą poszczególne alokacje. Jednak korzystanie z niego jest dość skomplikowane, a do tego nie zawsze udaje się go zastsosować i pożera ogromne zasoby. Jednak zdecydowanie warto spróbować, nie tylko do szukania wycieków pamięci czy szkodliwego kodu pląsającego po stercie zanieczyszczając cudze bufory.